Cộng đồng học thuật có lời giải thích mới cho việc ChatGPT trở nên ngu ngốc. Một nghiên cứu từ Đại học California, Santa Cruz cho biết: Đối với các tác vụ trước khi ngừng dữ liệu huấn luyện, mô hình lớn hoạt động tốt hơn đáng kể.
Bài viết tập trung vào vấn đề "ô nhiễm nhiệm vụ", tức là mô hình lớn đã nhìn thấy nhiều ví dụ về nhiệm vụ trong thời gian đào tạo, khiến mọi người có ấn tượng sai lầm rằng AI có khả năng không mẫu hoặc ít mẫu.

Một số học giả cũng chỉ ra từ một góc độ khác rằng các tham số của các mô hình lớn bị đóng băng sau khi đào tạo và mọi người tiếp tục đề xuất các nhiệm vụ mới, đồng nghĩa với việc phân bổ đầu vào liên tục thay đổi. Nếu mô hình không thể liên tục thích ứng với sự thay đổi này thì khả năng của nó sẽ dần suy giảm.
Mọi người cho rằng AI chỉ có thể trả lời một câu hỏi nhưng thực tế nó đã làm hầu hết các nhiệm vụ thông thường trong quá trình đào tạo.
Thời gian trôi qua và mọi người bắt đầu đặt ra nhiều câu hỏi mới hơn, hiệu suất của AI sẽ giảm sút.
Ví dụ, liên quan đến vấn đề mã, các ngôn ngữ lập trình tiếp tục phát triển và thay đổi, sớm hay muộn một ngày hiệu quả sẽ thấp đến mức không thể chấp nhận được. Đây là số phận của tất cả các mô hình không có khả năng học hỏi liên tục.

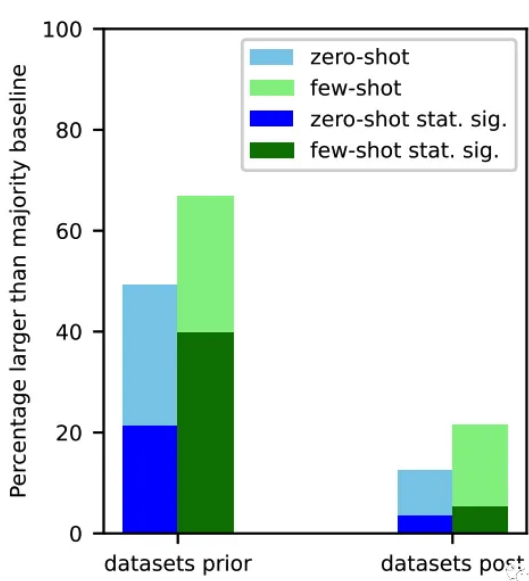
Tất cả họ đều có những vấn đề tương tự, đó là họ thực hiện nhiệm vụ tốt hơn đáng kể trước khi ngừng đào tạo
Việc đánh giá mức độ ô nhiễm của nhiệm vụ là rất khó khăn. Các mô hình nguồn đóng hoàn toàn không xuất bản dữ liệu đào tạo và hầu hết các mô hình nguồn mở chỉ liệt kê nguồn mà không xuất bản dữ liệu đó.
Nếu nhà nghiên cứu thu thập lại dữ liệu Internet, nó có thể đã thay đổi so với khi mô hình được huấn luyện.
Về vấn đề này, nhóm đã sử dụng 4 phương pháp để đo mức độ ô nhiễm của nhiệm vụ:
Kiểm tra dữ liệu huấn luyện : tìm kiếm trực tiếp các ví dụ nhiệm vụ tương ứng
Trên các mô hình nguồn mở Alpaca và Vicuna, có xu hướng rõ ràng về hiệu suất tốt hơn so với Llama ban đầu trong các nhiệm vụ ô nhiễm dữ liệu đào tạo.

Trích xuất các ví dụ về nhiệm vụ : Bằng cách điều chỉnh các từ gợi ý, hãy để mô hình tự đọc các ví dụ về nhiệm vụ trong dữ liệu huấn luyện
Từ phiên bản GPT-3 davinci-001 đến GPT-3.5-Turbo, vấn đề này ngày càng trở nên nghiêm trọng.
Trong hình, màu xám biểu thị rằng mô hình không có lệnh tinh chỉnh không thể lặp lại dữ liệu huấn luyện theo hướng dẫn từ nhắc, nhưng điều đó không có nghĩa là vấn đề không tồn tại.

Suy luận thành viên (chỉ khả dụng cho các tác vụ tạo): Kiểm tra xem các câu trả lời do mô hình tạo ra có giống hệt với dữ liệu gốc không.

Phân tích theo trình tự thời gian: Đối với các mô hình có thời gian thu thập dữ liệu huấn luyện đã biết, hãy đo lường hiệu suất trên các tập dữ liệu về thời gian phát hành đã biết và kiểm tra bằng chứng về ô nhiễm dữ liệu bằng cách sử dụng bằng chứng theo trình tự thời gian.
Ba phương pháp đầu tiên có độ chính xác cao hơn nhưng tỷ lệ thu hồi thấp hơn. Nếu tìm thấy dữ liệu trong dữ liệu huấn luyện của nhiệm vụ thì chắc chắn rằng nó đã xem các ví dụ.
Tuy nhiên, do những thay đổi về định dạng dữ liệu, thay đổi từ khóa và kích thước của tập dữ liệu, việc không tìm thấy bằng chứng bằng ba phương pháp đầu tiên không có nghĩa là dữ liệu không bị ô nhiễm.
Phương pháp thứ tư có tỷ lệ thu hồi cao nhưng độ chính xác thấp và dễ bị ảnh hưởng bởi các yếu tố nhiễu.
Đặc biệt đối với dòng GPT-3, hiện tại người ta cho rằng khả năng được cải thiện của nó là nhờ việc tinh chỉnh hướng dẫn, nhưng nhóm nghiên cứu tin rằng không phải như vậy.
Mặc dù hiệu suất của davinci-002 đã được cải thiện so với davinci-001 trên các tập dữ liệu trước năm 2021, nhưng hiệu suất đã giảm tương ứng trên các tập dữ liệu sau năm 2021.
Điều này cho thấy rằng dòng tinh chỉnh hướng dẫn GPT-3 chỉ hoạt động trên một số tập dữ liệu ban đầu nhất định.

Kết luận cuối cùng của nhóm là:
Do ô nhiễm nhiệm vụ, các mô hình nguồn đóng có thể hoạt động tốt hơn so với thực tế khi đánh giá không hoặc ít mẫu, đặc biệt là các mô hình được tinh chỉnh với RLHF. Mức độ ô nhiễm vẫn chưa rõ ràng, vì vậy bạn nên thận trọng.
Trong các thử nghiệm, các mô hình lớn hiếm khi cho thấy những cải thiện có ý nghĩa thống kê so với hầu hết các đường cơ sở trong cài đặt không và ít lần bắn cho các nhiệm vụ phân loại mà không có khả năng gây ô nhiễm nhiệm vụ.
Theo thời gian, người ta đã quan sát thấy sự gia tăng về hiệu suất không hoặc ít lần bắn của các mẫu dòng GPT-3 trong nhiều nhiệm vụ tiếp theo, có thể do nhiệm vụ bị nhiễm bẩn.
Ngay cả đối với các mô hình nguồn mở, việc kiểm tra dữ liệu đào tạo xem có bị nhiễm bẩn nhiệm vụ hay không là điều khó khăn.
Khuyến khích công bố công khai dữ liệu đào tạo để có thể kiểm tra các vấn đề ô nhiễm nhiệm vụ.
Bài viết tập trung vào vấn đề "ô nhiễm nhiệm vụ", tức là mô hình lớn đã nhìn thấy nhiều ví dụ về nhiệm vụ trong thời gian đào tạo, khiến mọi người có ấn tượng sai lầm rằng AI có khả năng không mẫu hoặc ít mẫu.
Một số học giả cũng chỉ ra từ một góc độ khác rằng các tham số của các mô hình lớn bị đóng băng sau khi đào tạo và mọi người tiếp tục đề xuất các nhiệm vụ mới, đồng nghĩa với việc phân bổ đầu vào liên tục thay đổi. Nếu mô hình không thể liên tục thích ứng với sự thay đổi này thì khả năng của nó sẽ dần suy giảm.
Mọi người cho rằng AI chỉ có thể trả lời một câu hỏi nhưng thực tế nó đã làm hầu hết các nhiệm vụ thông thường trong quá trình đào tạo.
Thời gian trôi qua và mọi người bắt đầu đặt ra nhiều câu hỏi mới hơn, hiệu suất của AI sẽ giảm sút.
Ví dụ, liên quan đến vấn đề mã, các ngôn ngữ lập trình tiếp tục phát triển và thay đổi, sớm hay muộn một ngày hiệu quả sẽ thấp đến mức không thể chấp nhận được. Đây là số phận của tất cả các mô hình không có khả năng học hỏi liên tục.
Mức độ ô nhiễm của sứ mệnh nghiêm trọng đến mức nào?
Nhóm nghiên cứu đã đánh giá tổng cộng 12 mẫu, từ dòng GPT-3, OPT và Bloom trước ChatGPT, cho đến GPT-3.5-turbo mới nhất, họ alpaca Llama, Alpaca và Vicuna.
Tất cả họ đều có những vấn đề tương tự, đó là họ thực hiện nhiệm vụ tốt hơn đáng kể trước khi ngừng đào tạo
Việc đánh giá mức độ ô nhiễm của nhiệm vụ là rất khó khăn. Các mô hình nguồn đóng hoàn toàn không xuất bản dữ liệu đào tạo và hầu hết các mô hình nguồn mở chỉ liệt kê nguồn mà không xuất bản dữ liệu đó.
Nếu nhà nghiên cứu thu thập lại dữ liệu Internet, nó có thể đã thay đổi so với khi mô hình được huấn luyện.
Về vấn đề này, nhóm đã sử dụng 4 phương pháp để đo mức độ ô nhiễm của nhiệm vụ:
Kiểm tra dữ liệu huấn luyện : tìm kiếm trực tiếp các ví dụ nhiệm vụ tương ứng
Trên các mô hình nguồn mở Alpaca và Vicuna, có xu hướng rõ ràng về hiệu suất tốt hơn so với Llama ban đầu trong các nhiệm vụ ô nhiễm dữ liệu đào tạo.
Trích xuất các ví dụ về nhiệm vụ : Bằng cách điều chỉnh các từ gợi ý, hãy để mô hình tự đọc các ví dụ về nhiệm vụ trong dữ liệu huấn luyện
Từ phiên bản GPT-3 davinci-001 đến GPT-3.5-Turbo, vấn đề này ngày càng trở nên nghiêm trọng.
Trong hình, màu xám biểu thị rằng mô hình không có lệnh tinh chỉnh không thể lặp lại dữ liệu huấn luyện theo hướng dẫn từ nhắc, nhưng điều đó không có nghĩa là vấn đề không tồn tại.
Suy luận thành viên (chỉ khả dụng cho các tác vụ tạo): Kiểm tra xem các câu trả lời do mô hình tạo ra có giống hệt với dữ liệu gốc không.
Phân tích theo trình tự thời gian: Đối với các mô hình có thời gian thu thập dữ liệu huấn luyện đã biết, hãy đo lường hiệu suất trên các tập dữ liệu về thời gian phát hành đã biết và kiểm tra bằng chứng về ô nhiễm dữ liệu bằng cách sử dụng bằng chứng theo trình tự thời gian.
Ba phương pháp đầu tiên có độ chính xác cao hơn nhưng tỷ lệ thu hồi thấp hơn. Nếu tìm thấy dữ liệu trong dữ liệu huấn luyện của nhiệm vụ thì chắc chắn rằng nó đã xem các ví dụ.
Tuy nhiên, do những thay đổi về định dạng dữ liệu, thay đổi từ khóa và kích thước của tập dữ liệu, việc không tìm thấy bằng chứng bằng ba phương pháp đầu tiên không có nghĩa là dữ liệu không bị ô nhiễm.
Phương pháp thứ tư có tỷ lệ thu hồi cao nhưng độ chính xác thấp và dễ bị ảnh hưởng bởi các yếu tố nhiễu.
Đặc biệt đối với dòng GPT-3, hiện tại người ta cho rằng khả năng được cải thiện của nó là nhờ việc tinh chỉnh hướng dẫn, nhưng nhóm nghiên cứu tin rằng không phải như vậy.
Mặc dù hiệu suất của davinci-002 đã được cải thiện so với davinci-001 trên các tập dữ liệu trước năm 2021, nhưng hiệu suất đã giảm tương ứng trên các tập dữ liệu sau năm 2021.
Điều này cho thấy rằng dòng tinh chỉnh hướng dẫn GPT-3 chỉ hoạt động trên một số tập dữ liệu ban đầu nhất định.
Do ô nhiễm nhiệm vụ, các mô hình nguồn đóng có thể hoạt động tốt hơn so với thực tế khi đánh giá không hoặc ít mẫu, đặc biệt là các mô hình được tinh chỉnh với RLHF. Mức độ ô nhiễm vẫn chưa rõ ràng, vì vậy bạn nên thận trọng.
Trong các thử nghiệm, các mô hình lớn hiếm khi cho thấy những cải thiện có ý nghĩa thống kê so với hầu hết các đường cơ sở trong cài đặt không và ít lần bắn cho các nhiệm vụ phân loại mà không có khả năng gây ô nhiễm nhiệm vụ.
Theo thời gian, người ta đã quan sát thấy sự gia tăng về hiệu suất không hoặc ít lần bắn của các mẫu dòng GPT-3 trong nhiều nhiệm vụ tiếp theo, có thể do nhiệm vụ bị nhiễm bẩn.
Ngay cả đối với các mô hình nguồn mở, việc kiểm tra dữ liệu đào tạo xem có bị nhiễm bẩn nhiệm vụ hay không là điều khó khăn.
Khuyến khích công bố công khai dữ liệu đào tạo để có thể kiểm tra các vấn đề ô nhiễm nhiệm vụ.
Theo VN review
